
ZooKeeper 程序员指南
开发使用 ZooKeeper 的分布式应用程序
- 简介
- ZooKeeper 数据模型
- ZooKeeper 会话
- ZooKeeper 监视
- 使用 ACL 的 ZooKeeper 访问控制
- 可插入的 ZooKeeper 身份验证
- 一致性保证
- 绑定
- 构建模块:ZooKeeper 操作指南
- 疑难解答:常见问题和故障排除
简介
本文档是希望创建利用 ZooKeeper 协调服务的分布式应用程序的开发人员的指南。它包含概念和实用信息。
本指南的前四部分对各种 ZooKeeper 概念进行了更高级别的讨论。这些对于理解 ZooKeeper 的工作原理以及如何使用它都是必要的。它不包含源代码,但它假设熟悉与分布式计算相关的问题。第一组中的部分是
接下来的四部分提供实用的编程信息。这些是
本书以附录结尾,其中包含指向其他有用的 ZooKeeper 相关信息的链接。
本文档中的大多数信息都写成可作为独立参考材料访问。但是,在启动第一个 ZooKeeper 应用程序之前,你可能至少应该阅读ZooKeeper 数据模型和ZooKeeper 基本操作的章节。
ZooKeeper 数据模型
ZooKeeper 具有分层命名空间,非常像分布式文件系统。唯一的区别是命名空间中的每个节点都可以具有与其关联的数据以及子节点。这就像拥有一个允许文件同时成为目录的文件系统。节点的路径始终表示为规范的、绝对的、用斜杠分隔的路径;没有相对引用。任何 Unicode 字符都可以在路径中使用,但须遵守以下约束
- 空字符 (\u0000) 不能是路径名称的一部分。(这会导致 C 绑定出现问题。)
- 以下字符不能使用,因为它们显示效果不佳或以令人困惑的方式呈现:\u0001 - \u001F 和 \u007F
- \u009F。
- 不允许使用以下字符:\ud800 - uF8FF、\uFFF0 - uFFFF。
- 字符“.”可以用作另一个名称的一部分,但“.”和“..”不能单独用于指示路径上的节点,因为 ZooKeeper 不使用相对路径。以下内容无效:“/a/b/./c”或“/a/b/../c”。
- 令牌“zookeeper”是保留的。
ZNode
ZooKeeper 树中的每个节点都称为znode。Znode 维护一个状态结构,其中包括数据更改和 acl 更改的版本号。状态结构还具有时间戳。版本号与时间戳一起允许 ZooKeeper 验证缓存并协调更新。每次 znode 的数据更改时,版本号都会增加。例如,每当客户端检索数据时,它还会接收数据的版本。当客户端执行更新或删除时,它必须提供要更改的 znode 的数据版本。如果它提供的版本与数据的实际版本不匹配,则更新将失败。(可以覆盖此行为。
注意
在分布式应用程序工程中,单词node可以指通用主机、服务器、集合成员、客户端进程等。在 ZooKeeper 文档中,znode指数据节点。服务器指构成 ZooKeeper 服务的机器;仲裁对等方指构成集合的服务器;客户端指使用 ZooKeeper 服务的任何主机或进程。
Znode 是程序员访问的主要实体。它们有几个值得在此提及的特性。
监视
客户端可以在 znode 上设置监视。对该 znode 的更改会触发监视,然后清除监视。当监视触发时,ZooKeeper 会向客户端发送通知。有关监视的更多信息,请参阅ZooKeeper 监视部分。
数据访问
存储在命名空间中每个 znode 中的数据以原子方式读取和写入。读取获取与 znode 关联的所有数据字节,而写入替换所有数据。每个节点都有一个访问控制列表 (ACL),用于限制谁可以做什么。
ZooKeeper 并非设计为通用数据库或大型对象存储。相反,它管理协调数据。此数据可以是配置、状态信息、集合点等形式。各种形式的协调数据的共同属性是它们相对较小:以千字节为单位。ZooKeeper 客户端和服务器实现具有健全性检查,以确保 znode 的数据少于 1M,但平均而言,数据应该远小于此。操作相对较大的数据大小将导致某些操作比其他操作花费更多时间,并且由于需要更多时间通过网络和存储介质移动更多数据,因此会影响某些操作的延迟。如果需要大数据存储,处理此类数据的通常模式是将其存储在批量存储系统(例如 NFS 或 HDFS)中,并将指向存储位置的指针存储在 ZooKeeper 中。
临时节点
ZooKeeper 还具有临时节点的概念。这些 znode 只要创建 znode 的会话处于活动状态就存在。当会话结束时,znode 将被删除。由于此行为,临时 znode 不允许有子节点。可以使用 getEphemerals() api 检索会话的临时列表。
getEphemerals()
检索会话为给定路径创建的临时节点列表。如果路径为空,它将列出会话的所有临时节点。用例 - 一个示例用例可能是,如果需要收集会话的临时节点列表以进行重复数据条目检查,并且节点以顺序方式创建,因此您不知道重复检查的名称。在这种情况下,可以使用 getEphemerals() api 获取会话的节点列表。这可能是服务发现的典型用例。
顺序节点——唯一命名
在创建 znode 时,您还可以请求 ZooKeeper 将单调递增的计数器追加到路径末尾。此计数器对父 znode 是唯一的。计数器的格式为 %010d -- 即 10 位数字,以 0(零)填充(计数器以这种方式格式化是为了简化排序),即“
容器节点
在 3.5.3 中添加
ZooKeeper 有容器 znode 的概念。容器 znode 是特殊用途的 znode,可用于配方,如领导者、锁等。当容器的最后一个子项被删除时,该容器将成为服务器在未来某个时间点删除的候选者。
鉴于此属性,您应该准备好在容器 znode 内创建子项时获取 KeeperException.NoNodeException。即在容器 znode 内创建子 znode 时,始终检查 KeeperException.NoNodeException,并在发生时重新创建容器 znode。
TTL 节点
在 3.5.3 中添加
在创建 PERSISTENT 或 PERSISTENT_SEQUENTIAL znode 时,您可以选择为 znode 设置 TTL(以毫秒为单位)。如果 znode 在 TTL 内未修改且没有子项,它将成为服务器在未来某个时间点删除的候选者。
注意:TTL 节点必须通过系统属性启用,因为它们默认情况下处于禁用状态。有关详细信息,请参见管理员指南。如果您尝试在未设置适当的系统属性的情况下创建 TTL 节点,服务器将抛出 KeeperException.UnimplementedException。
ZooKeeper 中的时间
ZooKeeper 以多种方式跟踪时间
- Zxid 对 ZooKeeper 状态的每次更改都会以zxid(ZooKeeper 事务 ID)的形式接收一个时间戳。这公开了对 ZooKeeper 的所有更改的总排序。每个更改都将具有唯一的 zxid,如果 zxid1 小于 zxid2,则 zxid1 发生在 zxid2 之前。
- 版本号 对节点的每次更改都会导致该节点的一个版本号增加。三个版本号为版本(对 znode 数据的更改次数)、cversion(对 znode 的子项的更改次数)和 aversion(对 znode 的 ACL 的更改次数)。
- 刻度 在使用多服务器 ZooKeeper 时,服务器使用刻度来定义事件的时间,例如状态上传、会话超时、对等方之间的连接超时等。刻度时间仅通过最小会话超时(刻度时间的 2 倍)间接公开;如果客户端请求的会话超时小于最小会话超时,服务器将告诉客户端会话超时实际上是最小会话超时。
- 实时 ZooKeeper 根本不使用实时或时钟时间,除了在创建 znode 和修改 znode 时将时间戳放入 stat 结构中。
ZooKeeper 统计结构
ZooKeeper 中每个 znode 的 Stat 结构由以下字段组成
- czxid 导致创建此 znode 的更改的 zxid。
- mzxid 最后修改此 znode 的更改的 zxid。
- pzxid 最后修改此 znode 的子项的更改的 zxid。
- ctime 此 znode 创建时的纪元时间(以毫秒为单位)。
- mtime 此 znode 最后修改时的纪元时间(以毫秒为单位)。
- version 此 znode 的数据更改次数。
- cversion 此 znode 的子项更改次数。
- aversion 此 znode 的 ACL 更改次数。
- ephemeralOwner 如果 znode 是临时节点,则此 znode 的所有者的会话 ID。如果不是临时节点,则为零。
- dataLength 此 znode 的数据字段的长度。
- numChildren 此 znode 的子项数量。
ZooKeeper 会话
ZooKeeper 客户端通过使用语言绑定创建到服务的句柄来与 ZooKeeper 服务建立会话。创建后,句柄从 CONNECTING 状态开始,客户端库尝试连接到组成 ZooKeeper 服务的其中一台服务器,此时它切换到 CONNECTED 状态。在正常操作期间,客户端句柄将处于这两个状态之一。如果发生无法恢复的错误(例如会话过期或身份验证失败),或者应用程序显式关闭句柄,则句柄将移至 CLOSED 状态。下图显示了 ZooKeeper 客户端可能的状态转换
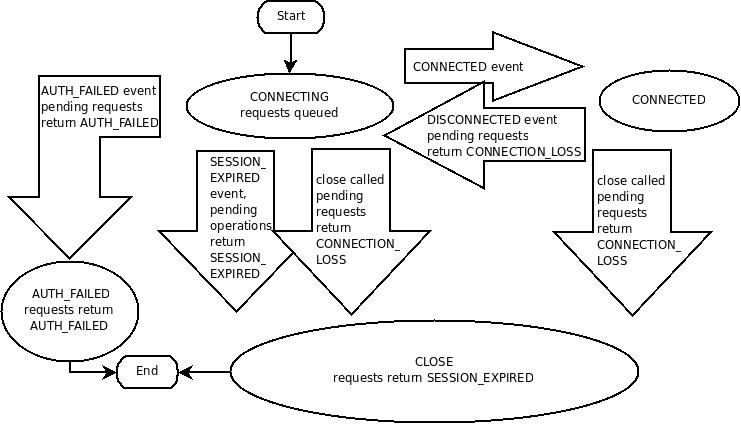
要创建客户端会话,应用程序代码必须提供一个连接字符串,其中包含以逗号分隔的主机:端口对列表,每个对都对应一个 ZooKeeper 服务器(例如“127.0.0.1:4545”或“127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002”)。ZooKeeper 客户端库将选择一个任意服务器并尝试连接到它。如果此连接失败,或者由于任何原因导致客户端与服务器断开连接,则客户端将自动尝试列表中的下一台服务器,直到(重新)建立连接。
在 3.2.0 中添加:还可以将可选的“chroot”后缀附加到连接字符串。这将在解释相对于此根的所有路径时运行客户端命令(类似于 unix chroot 命令)。如果使用,示例将如下所示:“127.0.0.1:4545/app/a”或“127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002/app/a”,其中客户端将根植于“/app/a”,所有路径都将相对于此根 - 即获取/设置/等...“/foo/bar”将导致在“/app/a/foo/bar”上运行操作(从服务器角度来看)。此功能在多租户环境中特别有用,其中特定 ZooKeeper 服务的每个用户都可以根植于不同的位置。这使得重用变得更加简单,因为每个用户都可以对其应用程序进行编码,就好像它根植于“/”,而实际位置(例如 /app/a)可以在部署时确定。
当客户端获取 ZooKeeper 服务的句柄时,ZooKeeper 会创建一个表示为 64 位数字的 ZooKeeper 会话,并将其分配给客户端。如果客户端连接到不同的 ZooKeeper 服务器,它会将会话 ID 作为连接握手的一部分发送。作为一项安全措施,服务器会为任何 ZooKeeper 服务器都可以验证的会话 ID 创建一个密码。当客户端建立会话时,密码会随会话 ID 一起发送给客户端。每当客户端使用新服务器重新建立会话时,它都会随会话 ID 一起发送此密码。
在 ZooKeeper 客户端库调用中创建 ZooKeeper 会话的参数之一是会话超时(以毫秒为单位)。客户端会发送请求的超时,服务器会响应它可以给客户端的超时。当前实现要求超时至少为 tickTime 的 2 倍(在服务器配置中设置),最多为 tickTime 的 20 倍。ZooKeeper 客户端 API 允许访问协商的超时。
当客户端(会话)与 ZK 服务集群断开连接时,它将开始搜索会话创建期间指定的服务器列表。最终,当客户端与至少一台服务器之间的连接重新建立时,会话将再次过渡到“已连接”状态(如果在会话超时值内重新连接),或者它将过渡到“已过期”状态(如果在会话超时后重新连接)。不建议为断开连接创建新的会话对象(新的 ZooKeeper.class 或 c 绑定中的 zookeeper 句柄)。ZK 客户端库将为您处理重新连接。特别是,我们在客户端库中内置了启发式方法来处理“羊群效应”等问题。仅在收到会话过期通知(强制)时才创建新会话。
会话过期由 ZooKeeper 集群本身管理,而不是由客户端管理。当 ZK 客户端与集群建立会话时,它会提供上面详细说明的“超时”值。集群使用此值来确定客户端会话何时过期。当集群在指定的会话超时期内没有收到客户端的消息(即没有心跳)时,就会发生过期。在会话过期时,集群将删除该会话拥有的任何/所有临时节点,并立即通知任何/所有已连接客户端更改(正在监视这些 znode 的任何人)。此时,已过期会话的客户端仍然与集群断开连接,除非它能够重新建立与集群的连接,否则它不会收到会话过期通知。客户端将一直处于断开连接状态,直到与集群重新建立 TCP 连接,此时已过期会话的观察者将收到“会话已过期”通知。
过期会话的观察者所看到的过期会话状态转换示例
- '已连接':会话已建立,客户端正在与集群通信(客户端/服务器通信正常运行)
- .... 客户端与集群断开连接
- '已断开连接':客户端已失去与集群的连接
- .... 时间流逝,在“超时”周期后,集群使会话过期,客户端未看到任何内容,因为它已与集群断开连接
- .... 时间流逝,客户端重新获得与集群的网络级连接
- '已过期':最终客户端重新连接到集群,然后收到过期通知
ZooKeeper 会话建立调用的另一个参数是默认观察者。当客户端中发生任何状态更改时,观察者会收到通知。例如,如果客户端失去与服务器的连接,客户端会收到通知,或者如果客户端的会话过期,等等... 此观察者应将初始状态视为已断开连接(即在客户端库向观察者发送任何状态更改事件之前)。对于新连接,发送给观察者的第一个事件通常是会话连接事件。
会话由客户端发送的请求保持活动状态。如果会话在一段时间内处于空闲状态,这将使会话超时,客户端将发送 PING 请求以保持会话活动状态。此 PING 请求不仅允许 ZooKeeper 服务器知道客户端仍然处于活动状态,还允许客户端验证其与 ZooKeeper 服务器的连接仍然处于活动状态。PING 的时序足够保守,以确保有足够的时间检测到死连接并重新连接到新服务器。
一旦与服务器的连接成功建立(已连接),当执行同步或异步操作时,客户端库会生成 connectionloss(c 绑定中的结果代码,Java 中的异常 -- 有关绑定特定详细信息,请参阅 API 文档)的情况主要有两种,其中之一成立
- 应用程序对不再活动/有效的会话调用操作
- 当有待处理操作时,ZooKeeper 客户端与服务器断开连接,即有待处理的异步调用。
在 3.2.0 中添加 -- SessionMovedException。有一个内部异常通常不会被客户端看到,称为 SessionMovedException。此异常发生是因为在不同服务器上重新建立会话的连接上收到了请求。此错误的常见原因是客户端向服务器发送请求,但网络数据包延迟,因此客户端超时并连接到新服务器。当延迟的数据包到达第一台服务器时,旧服务器检测到会话已移动,并关闭客户端连接。客户端通常不会看到此错误,因为它们不会从那些旧连接中读取。(旧连接通常已关闭。)当两个客户端尝试使用已保存的会话 ID 和密码重新建立同一连接时,可能会看到此条件。其中一个客户端将重新建立连接,而第二个客户端将断开连接(导致该对无限期地尝试重新建立其连接/会话)。
更新服务器列表。我们允许客户端通过提供一个新的逗号分隔的主机:端口对列表来更新连接字符串,每个都对应一个 ZooKeeper 服务器。该函数调用一个概率负载均衡算法,该算法可能导致客户端断开与当前主机的连接,目的是实现新列表中每个服务器的预期均匀连接数。如果客户端连接到的当前主机不在新列表中,则此调用将始终导致连接断开。否则,决策将基于服务器数量是否增加或减少以及增加或减少了多少。
例如,如果先前的连接字符串包含 3 个主机,而现在该列表包含这 3 个主机和另外 2 个主机,则连接到 3 个主机中每个主机的 40% 的客户端将移至一个新主机以平衡负载。该算法将导致客户端以概率 0.4 断开与当前已连接主机的连接,在这种情况下,导致客户端连接到 2 个新主机中随机选择的其中一个。
另一个示例——假设我们有 5 个主机,现在更新列表以删除其中 2 个主机,则连接到 3 个剩余主机的客户端将保持连接,而连接到 2 个已删除主机的所有客户端将需要移至 3 个主机中随机选择的一个。如果连接断开,客户端将进入一种特殊模式,在该模式下,它使用概率算法选择一个新的服务器进行连接,而不仅仅是循环。
在第一个示例中,每个客户端决定以概率 0.4 断开连接,但一旦做出决定,它将尝试连接到一个随机的新服务器,并且只有当它无法连接到任何新服务器时,它才会尝试连接到旧服务器。在找到服务器或尝试新列表中的所有服务器并连接失败后,客户端会返回到正常操作模式,在该模式下,它从 connectString 中选择一个任意服务器并尝试连接到它。如果失败,它将继续尝试循环中的不同随机服务器。(请参阅上面用于最初选择服务器的算法)
本地会话。在 3.5.0 中添加,主要由 ZOOKEEPER-1147 实现。
- 背景:在 ZooKeeper 中创建和关闭会话成本很高,因为它们需要法定人数确认,当 ZooKeeper 集群需要处理数千个客户端连接时,它们就成为瓶颈。因此,在 3.5.0 之后,我们引入了一种新型会话:本地会话,它没有普通(全局)会话的全部功能,此功能可以通过启用localSessionsEnabled来使用。
当localSessionsUpgradingEnabled被禁用时
-
本地会话无法创建临时节点
-
一旦本地会话丢失,用户就无法使用会话 ID/密码重新建立会话,会话及其监视将永久消失。注意:丢失 TCP 连接并不一定意味着会话丢失。如果在会话超时之前可以用相同的 zk 服务器重新建立连接,那么客户端可以继续(它只是不能移动到其他服务器)。
-
当本地会话连接时,会话信息仅保留在连接到的 Zookeeper 服务器上。领导者不知道此类会话的创建,并且没有状态写入磁盘。
-
ping、过期和其他会话状态维护由当前会话连接到的服务器处理。
当localSessionsUpgradingEnabled被启用时
-
本地会话可以自动升级到全局会话。
-
创建新会话时,它会保存在包装的LocalSessionTracker中。它随后可以根据需要升级到全局会话(例如创建临时节点)。如果请求升级,会话将从本地集合中删除,同时保留相同的会话 ID。
-
目前,只有操作:创建临时节点需要从本地升级到全局会话。原因是临时节点的创建在很大程度上依赖于全局会话。如果本地会话可以在不升级到全局会话的情况下创建临时节点,它将导致不同节点之间的数据不一致。领导者还需要了解会话的寿命,以便在关闭/过期时清理临时节点。这需要一个全局会话,因为本地会话与其特定服务器绑定。
-
在升级期间,会话可以同时是本地会话和全局会话,但两个线程不能同时调用升级操作。
-
ZooKeeperServer(独立)使用SessionTrackerImpl;LeaderZookeeper使用LeaderSessionTracker,它包含SessionTrackerImpl(全局)和LocalSessionTracker(如果启用);FollowerZooKeeperServer和ObserverZooKeeperServer使用LearnerSessionTracker,它包含LocalSessionTracker。有关会话的 UML 类图
+----------------+ +--------------------+ +---------------------+ | | --> | | ----> | LocalSessionTracker | | SessionTracker | | SessionTrackerImpl | +---------------------+ | | | | +-----------------------+ | | | | +-------------------------> | LeaderSessionTracker | +----------------+ +--------------------+ | +-----------------------+ | | | | | | | +---------------------------+ +---------> | | | UpgradeableSessionTracker | | | | | ------------------------+ +---------------------------+ | | | v +-----------------------+ | LearnerSessionTracker | +-----------------------+ -
问答
- 为什么会有禁用本地会话升级的配置选项?
- 在大规模部署中,它希望处理大量客户端,我们知道通过观察者连接的客户端应该只是本地会话。因此,这更像是防止有人意外创建大量临时节点和全局会话的保障措施。
-
会话何时创建?
- 在当前实现中,它将在处理ConnectRequest时尝试创建一个本地会话,并且当createSession请求到达FinalRequestProcessor时。
-
如果在服务器A上发送创建会话,并且客户端断开连接到最终发送该会话的其他服务器B,然后断开连接并重新连接到服务器A,会发生什么情况?
- 当客户端重新连接到B时,其sessionId将不会存在于B的本地会话跟踪器中。因此,B将发送验证数据包。如果A发出的CreateSession在验证数据包到达之前已提交,则客户端将能够连接。否则,客户端将因仲裁组尚未了解此会话而导致会话过期。如果客户端还尝试重新连接到A,则该会话已从本地会话跟踪器中删除。因此,A需要向领导者发送验证数据包。结果应与B相同,具体取决于请求的时间。
ZooKeeper 监视
ZooKeeper中的所有读取操作 - getData()、getChildren()和exists() - 都可以选择将监视作为副作用进行设置。以下是ZooKeeper对监视的定义:监视事件是一次性触发器,发送给设置监视的客户端,该事件在监视数据发生更改时发生。在这个监视定义中需要考虑三个关键点
- 一次性触发器当数据更改时,将向客户端发送一个监视事件。例如,如果客户端执行getData("/znode1", true),并且稍后/znode1的数据被更改或删除,则客户端将获得/znode1的监视事件。如果/znode1再次更改,则不会发送监视事件,除非客户端执行了另一个设置新监视的读取操作。
- 发送至客户端 这意味着事件正在发送至客户端,但可能在成功返回代码到达发起更改的客户端之前无法到达客户端。监视将异步发送至监视器。ZooKeeper 提供排序保证:客户端永远不会看到它已设置监视的更改,直到它首先看到监视事件。网络延迟或其他因素可能导致不同的客户端在不同时间看到监视和来自更新的返回代码。关键点在于,不同的客户端看到的所有内容都将具有一个一致的顺序。
- 设置监视的数据 这指代节点可以更改的不同方式。将 ZooKeeper 视为维护两个监视列表(数据监视和子监视)会有所帮助。getData() 和 exists() 设置数据监视。getChildren() 设置子监视。或者,将监视视为根据返回的数据类型设置可能会有所帮助。getData() 和 exists() 返回有关节点数据的信息,而 getChildren() 返回子列表。因此,setData() 将触发要设置的 znode 的数据监视(假设设置成功)。成功的 create() 将触发要创建的 znode 的数据监视和父 znode 的子监视。成功的 delete() 将触发要删除的 znode 的数据监视和子监视(因为不再有子项)以及父 znode 的子监视。
监视在客户端连接到的 ZooKeeper 服务器上本地维护。这允许监视轻量级设置、维护和调度。当客户端连接到新服务器时,将为任何会话事件触发监视。断开与服务器的连接时将不会收到监视。当客户端重新连接时,将重新注册任何先前注册的监视,并在需要时触发。通常,所有这些都以透明的方式发生。在一种情况下,监视可能会被错过:如果在断开连接时创建并删除了 znode,则将错过对尚未创建的 znode 存在的监视。
3.6.0 中的新增功能: 客户端还可以对 znode 设置永久的递归监视,这些监视在触发时不会被移除,并且会触发对已注册 znode 以及任何子 znode 的递归更改。
监视语义
我们可以使用读取 ZooKeeper 状态的三个调用来设置监视:exists、getData 和 getChildren。以下列表详细说明了监视可以触发的事件以及启用这些事件的调用
- 创建事件:通过调用 exists 启用。
- 删除事件:通过调用 exists、getData 和 getChildren 启用。
- 更改事件:通过调用 exists 和 getData 启用。
- 子级事件:通过调用 getChildren 启用。
持久递归监视
3.6.0 中的新增功能:现在对上面描述的标准监视进行了一种变体,您可以在其中设置一个在触发时不会被移除的监视。此外,这些监视触发事件类型NodeCreated、NodeDeleted 和 NodeDataChanged,并且可以选择对从注册监视的 znode 开始的所有 znode 递归执行此操作。请注意,不会为持久递归监视触发 NodeChildrenChanged 事件,因为这将是多余的。
使用 addWatch() 方法设置持久监视。触发语义和保证(一次性触发除外)与标准监视相同。关于事件的唯一例外是,递归持久监视器永远不会触发子级更改事件,因为它们是多余的。使用监视器类型 WatcherType.Any 的 removeWatches() 移除持久监视。
移除监视
我们可以使用 removeWatches 调用移除注册在 znode 上的监视。此外,即使没有服务器连接,ZooKeeper 客户端也可以通过将本地标志设置为 true 来本地移除监视。以下列表详细说明了在成功移除监视后将触发的事件。
- 子级移除事件:使用调用 getChildren 添加的监视器。
- 数据移除事件:使用调用 exists 或 getData 添加的监视器。
- 持久移除事件:使用调用添加持久监视的监视器。
ZooKeeper 对监视的保证
关于监视,ZooKeeper 保持以下保证
-
监视按其他事件、其他监视和异步回复的顺序排列。ZooKeeper 客户端库确保按顺序分派所有内容。
-
客户端将在看到与该 znode 对应的新数据之前看到对其正在监视的 znode 的监视事件。
-
ZooKeeper 中监视事件的顺序与 ZooKeeper 服务看到的更新顺序相对应。
关于监视需要记住的事项
-
标准监视是一次性触发器;如果您收到监视事件并且希望收到未来更改的通知,则必须设置另一个监视。
-
由于标准监视是一次性触发器,并且在获取事件和发送新请求以获取监视之间存在延迟,因此您无法可靠地看到 ZooKeeper 中节点发生的每次更改。请做好处理在获取事件和再次设置监视之间 znode 更改多次的情况的准备。(您可能不在乎,但至少意识到这种情况可能会发生。)
-
监视对象或函数/上下文对仅针对给定通知触发一次。例如,如果为同一文件注册了 exists 和 getData 调用,并且该文件随后被删除,则监视对象仅使用该文件的删除通知调用一次。
-
当您断开与服务器的连接(例如,当服务器发生故障时),在重新建立连接之前,您将不会收到任何监视。因此,会话事件将发送到所有未完成的监视处理程序。使用会话事件进入安全模式:在断开连接时您将不会收到事件,因此您的进程应在该模式下保守执行。
使用 ACL 的 ZooKeeper 访问控制
ZooKeeper 使用 ACL 控制对 znode(ZooKeeper 数据树的数据节点)的访问。ACL 实施与 UNIX 文件访问权限非常相似:它使用权限位来允许/禁止针对节点的各种操作以及位应用到的范围。与标准 UNIX 权限不同,ZooKeeper 节点不受用户(文件所有者)、组和世界(其他)这三个标准范围的限制。ZooKeeper 没有 znode 所有者的概念。相反,ACL 指定与这些 ID 关联的 ID 和权限集。
还要注意,ACL 仅适用于特定 znode。特别是,它不适用于子项。例如,如果 ip:172.16.16.1 只能读取 /app,而 /app/status 可供世界读取,则任何人都可以读取 /app/status;ACL 不是递归的。
ZooKeeper 支持可插拔的身份验证方案。ID 使用 scheme:expression 形式指定,其中 scheme 是 ID 对应的身份验证方案。有效表达式的集合由方案定义。例如,ip:172.16.16.1 是使用 ip 方案的地址为 172.16.16.1 的主机的 ID,而 digest:bob:password 是使用 digest 方案的名称为 bob 的用户的 ID。
当客户端连接到 ZooKeeper 并对自身进行身份验证时,ZooKeeper 会将所有对应于客户端的 ID 与客户端连接关联起来。当客户端尝试访问节点时,会根据 znode 的 ACL 检查这些 ID。ACL 由 (scheme:expression, perms) 对组成。expression 的格式特定于方案。例如,对 (ip:19.22.0.0/16, READ) 授予任何 IP 地址以 19.22 开头的客户端 READ 权限。
ACL 权限
ZooKeeper 支持以下权限
- CREATE:您可以创建子节点
- READ:您可以从节点获取数据并列出其子项。
- WRITE:您可以设置节点的数据
- DELETE:您可以删除子节点
- ADMIN:您可以设置权限
CREATE 和 DELETE 权限已从 WRITE 权限中分离出来,以实现更精细的访问控制。CREATE 和 DELETE 的情况如下
您希望 A 能够对 ZooKeeper 节点执行 set,但无法CREATE 或 DELETE 子项。
CREATE 无 DELETE:客户端通过在父目录中创建 ZooKeeper 节点来创建请求。您希望所有客户端都能添加,但只有请求处理器可以删除。(这有点像文件的 APPEND 权限。)
此外,ADMIN 权限存在,因为 ZooKeeper 没有任何文件所有者的概念。从某种意义上说,ADMIN 权限将实体指定为所有者。ZooKeeper 不支持 LOOKUP 权限(目录上的执行权限位,允许您进行 LOOKUP,即使您无法列出目录)。每个人都隐式拥有 LOOKUP 权限。这允许您对节点进行 stat,但仅此而已。(问题是,如果您想对不存在的节点调用 zoo_exists(),则没有权限检查。)
ADMIN 权限在 ACL 方面也具有特殊作用:为了检索 znode 的 ACL,用户必须具有 READ 或 ADMIN 权限,但如果没有 ADMIN 权限,则摘要哈希值将被屏蔽。
从版本 3.9.2 / 3.8.4 / 3.7.3 开始,exists() 调用现在将验证存在节点上的 ACL,并且客户端必须具有 READ 权限,否则将引发“权限不足”错误。
内置 ACL 方案
ZooKeeeper 具有以下内置方案
- world 具有一个 ID,anyone,代表任何人。
- auth 是一种特殊方案,它会忽略任何提供的表达式,而使用当前用户、凭据和方案。当 ZooKeeper 服务器在持久化 ACL 时,它会忽略提供的任何表达式(无论是像 SASL 认证那样的 user,还是像 DIGEST 认证那样的 user:password)。但是,ACL 中仍然必须提供表达式,因为 ACL 必须匹配 scheme:expression:perms 的形式。提供此方案是因为它是一个常见用例,即用户创建 znode,然后将对该 znode 的访问权限仅限制为该用户。如果没有经过身份验证的用户,则设置具有 auth 方案的 ACL 将会失败。
- digest 使用 username:password 字符串生成 MD5 哈希,然后将其用作 ACL ID 标识。通过以明文形式发送 username:password 来完成身份验证。在 ACL 中使用时,表达式将是 username:base64 编码的 SHA1 密码 digest。
- ip 使用客户端主机 IP 作为 ACL ID 标识。ACL 表达式采用 addr/bits 的形式,其中 addr 的最高有效 bits 与客户端主机 IP 的最高有效 bits 相匹配。
- x509 使用客户端 X500 主体作为 ACL ID 标识。ACL 表达式是客户端的 X500 主体名称。使用安全端口时,客户端会自动进行身份验证,并且会设置其 x509 方案的身份验证信息。
ZooKeeper C 客户端 API
ZooKeeper C 库提供了以下常量
- const int ZOO_PERM_READ; //可以读取节点的值并列出其子节点
- const int ZOO_PERM_WRITE;// 可以设置节点的值
- const int ZOO_PERM_CREATE; //可以创建子节点
- const int ZOO_PERM_DELETE;// 可以删除子节点
- const int ZOO_PERM_ADMIN; //可以执行 set_acl()
- const int ZOO_PERM_ALL;// 以上所有标志通过 OR 运算在一起
以下是标准 ACL ID
- struct Id ZOO_ANYONE_ID_UNSAFE; //(‘world’,’anyone’)
- struct Id ZOO_AUTH_IDS;// (‘auth’,’’)
ZOO_AUTH_IDS 空标识字符串应解释为“创建者的标识”。
ZooKeeper 客户端附带三个标准 ACL
- struct ACL_vector ZOO_OPEN_ACL_UNSAFE; //(ZOO_PERM_ALL,ZOO_ANYONE_ID_UNSAFE)
- struct ACL_vector ZOO_READ_ACL_UNSAFE;// (ZOO_PERM_READ, ZOO_ANYONE_ID_UNSAFE)
- struct ACL_vector ZOO_CREATOR_ALL_ACL; //(ZOO_PERM_ALL,ZOO_AUTH_IDS)
ZOO_OPEN_ACL_UNSAFE 完全开放,对所有 ACL 免费:任何应用程序都可以对节点执行任何操作,并且可以创建、列出和删除其子节点。ZOO_READ_ACL_UNSAFE 是任何应用程序的只读访问权限。CREATE_ALL_ACL 向节点的创建者授予所有权限。在使用此 ACL 创建节点之前,创建者必须经过服务器身份验证(例如,使用“digest”方案)。
以下 ZooKeeper 操作处理 ACL
- int zoo_add_auth (zhandle_t *zh,const char* scheme,const char* cert, int certLen, void_completion_t completion, const void *data);
该应用程序使用 zoo_add_auth 函数向服务器进行身份验证。如果应用程序希望使用不同的方案和/或身份进行身份验证,则可以多次调用该函数。
- int zoo_create (zhandle_t *zh, const char *path, const char *value,int valuelen, const struct ACL_vector *acl, int flags,char *realpath, int max_realpath_len);
zoo_create(...) 操作创建一个新节点。acl 参数是与该节点关联的 ACL 列表。父节点必须设置 CREATE 权限位。
- int zoo_get_acl (zhandle_t *zh, const char *path,struct ACL_vector *acl, struct Stat *stat);
此操作返回节点的 ACL 信息。该节点必须设置 READ 或 ADMIN 权限。如果没有 ADMIN 权限,则摘要哈希值将被屏蔽。
- int zoo_set_acl (zhandle_t *zh, const char *path, int version,const struct ACL_vector *acl);
此函数将节点的 ACL 列表替换为新的列表。该节点必须设置 ADMIN 权限。
以下是一个示例代码,它利用上述 API 使用“foo”方案进行身份验证,并创建具有仅创建权限的临时节点“/xyz”。
注意
这是一个非常简单的示例,旨在展示如何与 ZooKeeper ACL 特别交互。有关 C 客户端实现的示例,请参阅 .../trunk/zookeeper-client/zookeeper-client-c/src/cli.c
#include <string.h>
#include <errno.h>
#include "zookeeper.h"
static zhandle_t *zh;
/**
* In this example this method gets the cert for your
* environment -- you must provide
*/
char *foo_get_cert_once(char* id) { return 0; }
/** Watcher function -- empty for this example, not something you should
* do in real code */
void watcher(zhandle_t *zzh, int type, int state, const char *path,
void *watcherCtx) {}
int main(int argc, char argv) {
char buffer[512];
char p[2048];
char *cert=0;
char appId[64];
strcpy(appId, "example.foo_test");
cert = foo_get_cert_once(appId);
if(cert!=0) {
fprintf(stderr,
"Certificate for appid [%s] is [%s]\n",appId,cert);
strncpy(p,cert, sizeof(p)-1);
free(cert);
} else {
fprintf(stderr, "Certificate for appid [%s] not found\n",appId);
strcpy(p, "dummy");
}
zoo_set_debug_level(ZOO_LOG_LEVEL_DEBUG);
zh = zookeeper_init("localhost:3181", watcher, 10000, 0, 0, 0);
if (!zh) {
return errno;
}
if(zoo_add_auth(zh,"foo",p,strlen(p),0,0)!=ZOK)
return 2;
struct ACL CREATE_ONLY_ACL[] = {{ZOO_PERM_CREATE, ZOO_AUTH_IDS}};
struct ACL_vector CREATE_ONLY = {1, CREATE_ONLY_ACL};
int rc = zoo_create(zh,"/xyz","value", 5, &CREATE_ONLY, ZOO_EPHEMERAL,
buffer, sizeof(buffer)-1);
/** this operation will fail with a ZNOAUTH error */
int buflen= sizeof(buffer);
struct Stat stat;
rc = zoo_get(zh, "/xyz", 0, buffer, &buflen, &stat);
if (rc) {
fprintf(stderr, "Error %d for %s\n", rc, __LINE__);
}
zookeeper_close(zh);
return 0;
}
可插入的 ZooKeeper 身份验证
ZooKeeper 在具有各种不同身份验证方案的各种不同环境中运行,因此它具有完全可插拔的身份验证框架。即使内置的身份验证方案也使用可插拔的身份验证框架。
要了解验证框架的工作原理,您必须首先了解两个主要的验证操作。该框架首先必须验证客户端。这通常在客户端连接到服务器后立即完成,包括验证从客户端发送或收集的信息,并将其与连接关联。该框架处理的第二个操作是查找与客户端对应的 ACL 中的条目。ACL 条目是 <idspec、permissions> 对。idspec 可以是对与连接关联的验证信息进行的简单字符串匹配,也可以是对该信息进行评估的表达式。由验证插件的实现来进行匹配。以下为验证插件必须实现的接口
public interface AuthenticationProvider {
String getScheme();
KeeperException.Code handleAuthentication(ServerCnxn cnxn, byte authData[]);
boolean isValid(String id);
boolean matches(String id, String aclExpr);
boolean isAuthenticated();
}
第一个方法 getScheme 返回标识该插件的字符串。由于我们支持多种验证方法,因此验证凭据或 idspec 将始终以 scheme: 为前缀。ZooKeeper 服务器使用验证插件返回的方案来确定该方案适用于哪些 id。
当客户端发送要与连接关联的验证信息时,将调用 handleAuthentication。客户端指定信息所对应方案。ZooKeeper 服务器将信息传递给其 getScheme 与客户端传递的方案匹配的验证插件。如果 handleAuthentication 的实现者确定信息错误,它通常会返回一个错误,或者它将使用 cnxn.getAuthInfo().add(new Id(getScheme(), data)) 将信息与连接关联。
验证插件参与设置和使用 ACL。当为 znode 设置 ACL 时,ZooKeeper 服务器会将条目的 id 部分传递给 isValid(String id) 方法。由插件验证 id 是否具有正确的形式。例如,ip:172.16.0.0/16 是一个有效的 id,但 ip:host.com 不是。如果新的 ACL 包含“auth”条目,则使用 isAuthenticated 来查看是否应将与连接关联的该方案的验证信息添加到 ACL。某些方案不应包含在 auth 中。例如,如果指定了 auth,则客户端的 IP 地址不被视为应添加到 ACL 的 id。
ZooKeeper 在检查 ACL 时调用 matches(String id, String aclExpr)。它需要将客户端的验证信息与相关的 ACL 条目进行匹配。为了找到适用于客户端的条目,ZooKeeper 服务器将查找每个条目的方案,如果存在来自该客户端的该方案的验证信息,则将使用 id 设置为先前通过 handleAuthentication 添加到连接的验证信息,并使用 aclExpr 设置为 ACL 条目的 id 来调用 matches(String id, String aclExpr)。验证插件使用自己的逻辑和匹配方案来确定 id 是否包含在 aclExpr 中。
有两个内置的验证插件:ip 和 digest。可以使用系统属性添加其他插件。在启动时,ZooKeeper 服务器将查找以“zookeeper.authProvider.”开头的系统属性,并将这些属性的值解释为验证插件的类名。可以使用 -Dzookeeeper.authProvider.X=com.f.MyAuth 设置这些属性,或在服务器配置文件中添加以下条目
authProvider.1=com.f.MyAuth
authProvider.2=com.f.MyAuth2
应小心确保属性的后缀是唯一的。如果存在重复项,例如 -Dzookeeeper.authProvider.X=com.f.MyAuth -Dzookeeper.authProvider.X=com.f.MyAuth2,则只会使用一个。此外,所有服务器都必须定义相同的插件,否则使用插件提供的身份验证方案的客户端将无法连接到某些服务器。
在 3.6.0 中添加:可用于可插入式身份验证的备用抽象。它提供其他参数。
public abstract class ServerAuthenticationProvider implements AuthenticationProvider {
public abstract KeeperException.Code handleAuthentication(ServerObjs serverObjs, byte authData[]);
public abstract boolean matches(ServerObjs serverObjs, MatchValues matchValues);
}
不要实现 AuthenticationProvider,而是扩展 ServerAuthenticationProvider。然后,handleAuthentication() 和 matches() 方法将接收其他参数(通过 ServerObjs 和 MatchValues)。
- ZooKeeperServer ZooKeeperServer 实例
- ServerCnxn 当前连接
- path 正在操作的 ZNode 路径(或在不使用时为 null)
- perm 操作值或 0
- 在对 setAcl() 方法进行操作时,setAcls 正在设置的 ACL 列表
一致性保证
ZooKeeper 是一种高性能、可扩展的服务。读取和写入操作都设计为快速,但读取速度比写入速度快。原因在于,在读取的情况下,ZooKeeper 可以提供较旧的数据,而这反过来又归因于 ZooKeeper 的一致性保证
-
顺序一致性:来自客户端的更新将按发送顺序应用。
-
原子性:更新要么成功,要么失败——没有部分结果。
-
单一系统映像:客户端将看到相同服务视图,无论连接到哪个服务器。即,即使客户端使用相同的会话故障转移到不同的服务器,客户端也永远不会看到较旧的系统视图。
-
可靠性:一旦应用更新,它将从那时起一直持续到客户端覆盖更新。此保证有两个推论
- 如果客户端获得成功的返回代码,则更新将已应用。在某些故障(通信错误、超时等)中,客户端将不知道更新是否已应用。我们采取措施最大程度地减少故障,但只有在返回代码成功的情况下才存在此保证。(在 Paxos 中,这称为单调性条件。)
- 客户端通过读取请求或成功的更新看到的所有更新在从服务器故障中恢复时永远不会回滚。
-
及时性:系统对客户端的视图在一定的时间范围内(在几十秒的范围内)保证是最新的。系统更改将在该范围内被客户端看到,或者客户端将检测到服务中断。
使用这些一致性保证,可以轻松构建更高级别的函数,例如领导者选举、屏障、队列和读/写可撤销锁,仅在 ZooKeeper 客户端(无需对 ZooKeeper 进行添加)中。有关更多详细信息,请参阅配方和解决方案。
注意
有时开发人员错误地假设了 ZooKeeper 实际上没有做出的另一个保证。这是:*同时一致的跨客户端视图*:ZooKeeper 并不保证在任何时间实例中,两个不同的客户端都将具有 ZooKeeper 数据的相同视图。由于网络延迟等因素,一个客户端可能会在另一个客户端收到更改通知之前执行更新。考虑两个客户端 A 和 B 的场景。如果客户端 A 将 znode /a 的值从 0 设置为 1,然后告诉客户端 B 读取 /a,则客户端 B 可能会读取旧值 0,具体取决于它连接到的服务器。如果客户端 A 和客户端 B 读取相同的值很重要,则客户端 B 应在执行读取之前从 ZooKeeper API 方法调用sync()方法。因此,ZooKeeper 本身并不能保证更改在所有服务器上同步发生,但 ZooKeeper 原语可用于构建提供有用的客户端同步的高级功能。(有关更多信息,请参阅ZooKeeper 配方。
绑定
ZooKeeper 客户端库有两种语言:Java 和 C。以下部分对此进行了描述。
Java 绑定
有两个包组成了 ZooKeeper Java 绑定:org.apache.zookeeper 和 org.apache.zookeeper.data。组成 ZooKeeper 的其余包在内部使用或作为服务器实现的一部分。org.apache.zookeeper.data 包由生成类组成,这些类仅用作容器。
ZooKeeper Java 客户端使用的主要类是ZooKeeper类。它的两个构造函数仅通过可选的会话 ID 和密码有所不同。ZooKeeper 支持跨进程实例进行会话恢复。Java 程序可以将其会话 ID 和密码保存到稳定存储中,重新启动并恢复程序的早期实例使用的会话。
创建 ZooKeeper 对象时,也会创建两个线程:IO 线程和事件线程。所有 IO 都在 IO 线程上发生(使用 Java NIO)。所有事件回调都在事件线程上发生。会话维护(例如重新连接到 ZooKeeper 服务器和维护心跳)在 IO 线程上完成。同步方法的响应也在 IO 线程中处理。对异步方法和监视事件的所有响应都在事件线程上处理。该设计导致了一些需要注意的事项
- 对异步调用和观察者回调的所有完成都将按顺序进行,一次一个。调用者可以执行他们希望的任何处理,但在此期间不会处理任何其他回调。
- 回调不会阻止 IO 线程的处理或同步调用的处理。
- 同步调用可能不会按正确顺序返回。例如,假设客户端执行以下处理:对节点/a发出异步读取,将监视设置为 true,然后在读取的完成回调中对/a执行同步读取。(可能不是好习惯,但也不是非法的,而且它是一个简单的示例。)请注意,如果在异步读取和同步读取之间对/a进行了更改,客户端库将收到监视事件,指出/a在同步读取的响应之前已更改,但由于完成回调阻止了事件队列,因此同步读取将在处理监视事件之前返回/a的新值。
最后,与关闭相关的规则很简单:一旦 ZooKeeper 对象关闭或收到致命事件(SESSION_EXPIRED 和 AUTH_FAILED),ZooKeeper 对象就会变为无效。在关闭时,两个线程关闭,并且对 zookeeper 句柄的任何进一步访问都是未定义的行为,应避免这样做。
客户端配置参数
以下列表包含 Java 客户端的配置属性。您可以使用 Java 系统属性设置其中任何属性。对于服务器属性,请查看管理员指南的服务器配置部分。ZooKeeper Wiki 还有关于ZooKeeper SSL 支持和ZooKeeper 的 SASL 身份验证的有用页面。
-
zookeeper.sasl.client:将值设置为false以禁用 SASL 身份验证。默认值为true。
-
zookeeper.sasl.clientconfig:指定 JAAS 登录文件中的上下文密钥。默认值为“Client”。
-
zookeeper.server.principal:当启用 Kerberos 身份验证时,指定客户端用于连接到 zookeeper 服务器的身份验证的服务器主体。如果提供了此配置,则 ZooKeeper 客户端将不会使用以下任何参数来确定服务器主体:zookeeper.sasl.client.username、zookeeper.sasl.client.canonicalize.hostname、zookeeper.server.realm。注意:此配置参数仅适用于 ZooKeeper 3.5.7+、3.6.0+。
-
zookeeper.sasl.client.username:传统上,主体分为三个部分:主、实例和域。典型的 Kerberos V5 主体的格式为 primary/instance@REALM。zookeeper.sasl.client.username 指定服务器主体的 primary 部分。默认值为“zookeeper”。实例部分源自服务器 IP。最后,服务器的主体是 username/IP@realm,其中 username 是 zookeeper.sasl.client.username 的值,IP 是服务器 IP,realm 是 zookeeper.server.realm 的值。
-
zookeeper.sasl.client.canonicalize.hostname:预期未提供 zookeeper.server.principal 参数,ZooKeeper 客户端将尝试确定 ZooKeeper 服务器主体的“实例”(主机)部分。首先,它获取作为 ZooKeeper 服务器连接字符串提供的 hostname。然后,它尝试通过获取属于该地址的完全限定域名来“规范化”该地址。你可以通过设置 zookeeper.sasl.client.canonicalize.hostname=false 来禁用此“规范化”。
-
zookeeper.server.realm:服务器主体的域部分。默认情况下,它是客户端主体域。
-
zookeeper.disableAutoWatchReset:此开关控制是否启用自动监视重置。默认情况下,客户端在会话重新连接期间自动重置监视,此选项允许客户端通过将 zookeeper.disableAutoWatchReset 设置为 true 来关闭此行为。
-
zookeeper.client.secure:3.5.5 中的新增功能:如果你想连接到服务器安全客户端端口,则需要在客户端上将此属性设置为 true。这将使用指定的凭据通过 SSL 连接到服务器。请注意,它需要 Netty 客户端。
-
zookeeper.clientCnxnSocket:指定要使用的 ClientCnxnSocket。可能的值为 org.apache.zookeeper.ClientCnxnSocketNIO 和 org.apache.zookeeper.ClientCnxnSocketNetty。默认值为 org.apache.zookeeper.ClientCnxnSocketNIO。如果您想连接到服务器的安全客户端端口,则需要在客户端上将此属性设置为 org.apache.zookeeper.ClientCnxnSocketNetty。
-
zookeeper.ssl.keyStore.location 和 zookeeper.ssl.keyStore.password:3.5.5 中的新增功能:指定包含用于 SSL 连接的本地凭据的 JKS 的文件路径以及用于解锁该文件的文件密码。
-
zookeeper.ssl.keyStore.passwordPath:3.8.0 中的新增功能:指定包含密钥库密码的文件路径
-
zookeeper.ssl.trustStore.location 和 zookeeper.ssl.trustStore.password:3.5.5 中的新增功能:指定包含用于 SSL 连接的远程凭据的 JKS 的文件路径以及用于解锁该文件的文件密码。
-
zookeeper.ssl.trustStore.passwordPath:3.8.0 中的新增功能:指定包含信任库密码的文件路径
-
zookeeper.ssl.keyStore.type 和 zookeeper.ssl.trustStore.type:3.5.5 中的新增功能:指定用于建立与 ZooKeeper 服务器的 TLS 连接的密钥/信任库文件的格式。值:JKS、PEM、PKCS12 或 null(按文件名检测)。默认值:null。3.6.3、3.7.0 中的新增功能:添加了 BCFKS 格式。
-
jute.maxbuffer:在客户端中,它指定来自服务器的传入数据的最大大小。默认值为 0xfffff(1048575) 字节,或略低于 1M。这实际上是一种健全性检查。ZooKeeper 服务器旨在存储和发送千字节级的数据。如果传入数据长度大于此值,则会引发 IOException。客户端的此值应与服务器端保持一致(在客户端中设置 System.setProperty("jute.maxbuffer", "xxxx") 将起作用),否则会出现问题。
-
zookeeper.kinit:指定 kinit 二进制文件的路径。默认值为 "/usr/bin/kinit"。
C 绑定
C 绑定具有单线程和多线程库。多线程库最易于使用,并且与 Java API 最为相似。此库将创建一个 IO 线程和一个事件分发线程,用于处理连接维护和回调。单线程库通过公开多线程库中使用的事件循环,允许在事件驱动应用程序中使用 ZooKeeper。
该软件包包含两个共享库:zookeeper_st 和 zookeeper_mt。前者仅提供异步 API 和回调,用于集成到应用程序的事件循环中。此库存在的唯一原因是支持没有提供 pthread 库或该库不稳定的平台(即 FreeBSD 4.x)。在所有其他情况下,应用程序开发人员都应链接到 zookeeper_mt,因为它同时支持同步和异步 API。
安装
如果您要从 Apache 存储库检出构建客户端,请按照以下步骤操作。如果您要从 Apache 下载的项目源软件包构建,请跳至步骤 3。
- 在 zookeeper-jute 目录(.../trunk/zookeeper-jute)中运行
mvn compile。这将在 .../trunk/zookeeper-client/zookeeper-client-c 下创建一个名为“generated”的目录。 - 将目录更改为*.../trunk/zookeeper-client/zookeeper-client-c* 并运行
autoreconf -if以引导 autoconf、automake 和 libtool。确保已安装 autoconf 版本 2.59 或更高版本。跳至步骤4。 - 如果您要从项目源软件包构建,请解压/解包源 tarball 并 cd 到* zookeeper-x.x.x/zookeeper-client/zookeeper-client-c* 目录。
- 运行
./configure <your-options>以生成 makefile。以下是 configure 实用程序支持的一些选项,这些选项在此步骤中可能有用
--enable-debug启用优化并启用调试信息编译器选项。(默认情况下禁用。)--without-syncapi禁用同步 API 支持;不会构建 zookeeper_mt 库。(默认情况下启用。)--disable-static不构建静态库。(默认情况下启用。)--disable-shared不构建共享库。(默认情况下启用。)
注意
有关运行 configure 的一般信息,请参阅 INSTALL。1. 运行
make或make install以构建库并安装它们。1. 要生成 ZooKeeper API 的 doxygen 文档,请运行make doxygen-doc。所有文档都将放置在一个名为 docs 的新子文件夹中。默认情况下,此命令仅生成 HTML。有关其他文档格式的信息,请运行./configure --help
构建自己的 C 客户端
为了能够在应用程序中使用 ZooKeeper C API,您必须记住
- 包含 ZooKeeper 头文件:
#include <zookeeper/zookeeper.h> - 如果您正在构建多线程客户端,请使用
-DTHREADED编译器标志进行编译以启用该库的多线程版本,然后链接到 zookeeper_mt 库。如果您正在构建单线程客户端,请不要使用-DTHREADED进行编译,并确保链接到_zookeeper_st_库。
注意
有关 C 客户端实现的示例,请参阅 .../trunk/zookeeper-client/zookeeper-client-c/src/cli.c
构建模块:ZooKeeper 操作指南
本部分调查了开发人员可以在 ZooKeeper 服务器上执行的所有操作。它比本手册中较早的概念章节中的信息级别低,但比 ZooKeeper API 参考中的信息级别高。它涵盖了以下主题
处理错误
Java 和 C 客户端绑定都可能报告错误。Java 客户端绑定通过抛出 KeeperException 来执行此操作,对异常调用 code() 将返回特定错误代码。C 客户端绑定返回 ZOO_ERRORS 枚举中定义的错误代码。API 回调指示两种语言绑定的结果代码。有关可能错误及其含义的完整详细信息,请参阅 API 文档(Java 的 javadoc,C 的 doxygen)。
连接到 ZooKeeper
在开始之前,您必须设置一个正在运行的 Zookeeper 服务器,以便我们可以开始开发客户端。对于 C 客户端绑定,我们将使用多线程库 (zookeeper_mt) 以及用 C 编写的简单示例。要与 Zookeeper 服务器建立连接,我们使用 C API - zookeeper_init,其签名如下
int zookeeper_init(const char *host, watcher_fn fn, int recv_timeout, const clientid_t *clientid, void *context, int flags);
-
*host:连接字符串到 Zookeeper 服务器,格式为 host:port。如果有多个服务器,请在指定 host:port 对后使用逗号作为分隔符。例如:“127.0.0.1:2181,127.0.0.1:3001,127.0.0.1:3002”
-
fn:监视器函数,用于在触发通知时处理事件。
-
recv_timeout:会话过期时间(以毫秒为单位)。
-
*clientid:我们可以为新会话指定 0。如果会话之前已经建立,我们可以提供该客户端 ID,它将重新连接到该先前会话。
-
*context:可以与 zkhandle_t 处理程序关联的上下文对象。如果未使用,我们可以将其设置为 0。
-
flags:在初始化时,我们可以将其保留为 0。
我们将演示在成功连接后输出“已连接到 Zookeeper”的客户端,否则输出错误消息。我们称以下代码为 zkClient.cc
#include <stdio.h>
#include <zookeeper/zookeeper.h>
#include <errno.h>
using namespace std;
// Keeping track of the connection state
static int connected = 0;
static int expired = 0;
// *zkHandler handles the connection with Zookeeper
static zhandle_t *zkHandler;
// watcher function would process events
void watcher(zhandle_t *zkH, int type, int state, const char *path, void *watcherCtx)
{
if (type == ZOO_SESSION_EVENT) {
// state refers to states of zookeeper connection.
// To keep it simple, we would demonstrate these 3: ZOO_EXPIRED_SESSION_STATE, ZOO_CONNECTED_STATE, ZOO_NOTCONNECTED_STATE
// If you are using ACL, you should be aware of an authentication failure state - ZOO_AUTH_FAILED_STATE
if (state == ZOO_CONNECTED_STATE) {
connected = 1;
} else if (state == ZOO_NOTCONNECTED_STATE ) {
connected = 0;
} else if (state == ZOO_EXPIRED_SESSION_STATE) {
expired = 1;
connected = 0;
zookeeper_close(zkH);
}
}
}
int main(){
zoo_set_debug_level(ZOO_LOG_LEVEL_DEBUG);
// zookeeper_init returns the handler upon a successful connection, null otherwise
zkHandler = zookeeper_init("localhost:2181", watcher, 10000, 0, 0, 0);
if (!zkHandler) {
return errno;
}else{
printf("Connection established with Zookeeper. \n");
}
// Close Zookeeper connection
zookeeper_close(zkHandler);
return 0;
}
使用前面提到的多线程库编译代码。
> g++ -Iinclude/ zkClient.cpp -lzookeeper_mt -o Client
运行客户端。
> ./Client
从输出中,如果连接成功,您应该看到“已连接到 Zookeeper”以及 Zookeeper 的 DEBUG 消息。
疑难解答:常见问题和故障排除
现在您已经了解了 ZooKeeper。它快速、简单,您的应用程序可以正常工作,但是等等……有些地方出了问题。以下是 ZooKeeper 用户会遇到的部分陷阱
- 如果您正在使用监视,则必须查找已连接的监视事件。当 ZooKeeper 客户端与服务器断开连接时,在重新连接之前,您将不会收到更改通知。如果您正在监视 znode 出现,则如果在您断开连接时创建并删除了 znode,您将错过该事件。
- 您必须测试 ZooKeeper 服务器故障。只要大多数服务器处于活动状态,ZooKeeper 服务就可以在故障中存活下来。要问的问题是:您的应用程序能否处理它?在现实世界中,客户端与 ZooKeeper 的连接可能会中断。(ZooKeeper 服务器故障和网络分区是连接丢失的常见原因。)ZooKeeper 客户端库负责恢复您的连接并告知您发生了什么,但您必须确保恢复您的状态和任何失败的未完成请求。找出您是否在测试实验室中做对了,而不是在生产中 - 使用由多个服务器组成的 ZooKeeper 服务进行测试,并让它们重新启动。
- 客户端使用的 ZooKeeper 服务器列表必须与每个 ZooKeeper 服务器的 ZooKeeper 服务器列表匹配。如果客户端列表是 ZooKeeper 服务器真实列表的子集,则事情可以正常工作,尽管不是最佳状态,但如果客户端列出了 ZooKeeper 集群中不存在的 ZooKeeper 服务器,则不行。
- 小心放置事务日志。ZooKeeper 中性能最关键的部分是事务日志。ZooKeeper 必须在返回响应之前将事务同步到媒体。专用事务日志设备是始终保持良好性能的关键。将日志放在繁忙的设备上会对性能产生不利影响。如果您只有一个存储设备,请将跟踪文件放在 NFS 上并增加 snapshotCount;它不能消除问题,但可以缓解问题。
- 正确设置 Java 最大堆大小。避免交换非常重要。不必要地转到磁盘几乎肯定会使您的性能下降到不可接受的程度。请记住,在 ZooKeeper 中,所有内容都是按顺序排列的,因此如果一个请求命中磁盘,所有其他排队请求都会命中磁盘。为了避免交换,请尝试将堆大小设置为您的物理内存量,减去操作系统和缓存所需的量。确定配置的最佳堆大小的最佳方法是运行负载测试。如果您由于某种原因无法做到,请保守估计,并选择一个远低于导致您的机器交换的限制的数字。例如,在 4G 机器上,3G 堆是一个保守的估计,可以从这里开始。
其他信息的链接
除了正式文档之外,还有其他几个 ZooKeeper 开发人员的信息来源。
-
API 参考:ZooKeeper API 的完整参考
-
2008 年 Hadoop 峰会上 ZooKeeper 演讲:雅虎研究的 Benjamin Reed 对 ZooKeeper 的视频介绍
-
屏障和队列教程:Flavio Junqueira 出色的 Java 教程,使用 ZooKeeper 实现简单的屏障和生产者-消费者队列。
-
ZooKeeper - 一个可靠、可扩展的分布式协调系统:Todd Hoff 的一篇文章(2008 年 7 月 15 日)
-
ZooKeeper 配方:使用 ZooKeeper 实现各种同步解决方案的伪级别讨论:事件句柄、队列、锁和两阶段提交。